微积分与梯度
梯度下降是深度学习训练的核心引擎。理解导数和链式法则,就理解了神经网络如何学习。
一、导数基础
1.1 导数的定义
导数描述函数在某点的变化率:
直觉理解:如果
1.2 常用导数公式
| 函数 | 导数 | 备注 |
|---|---|---|
| 幂函数 | ||
| 指数函数求导等于自身 | ||
| 自然对数 | ||
1.3 导数运算规则
加法法则:
乘法法则:
除法法则:
链式法则(最重要!):
或写作:
二、极大值与极小值
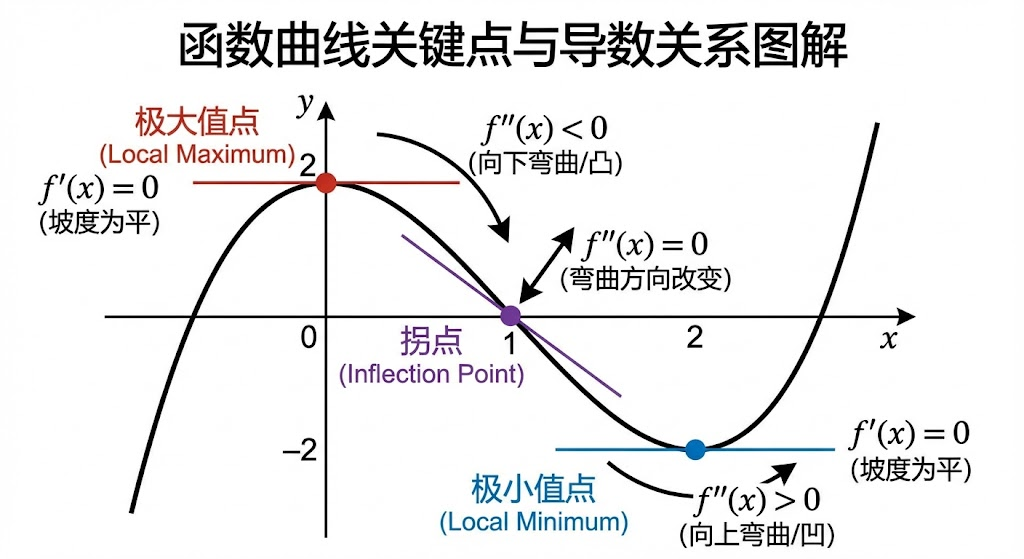
- 极大值:函数在该点左侧递增,右侧递减,导数在该点为 0 且从正变负
- 极小值:函数在该点左侧递减,右侧递增,导数在该点为 0 且从负变正
- 拐点:函数曲率改变的点,二阶导数为 0
在机器学习中,我们寻找损失函数的极小值点,那就是最优参数所在的地方。
临界点判断方法
对于函数
- 若
: 是极小值点 - 若
: 是极大值点 - 若
:需进一步判断
三、偏导数
当函数有多个变量时,偏导数是对其中一个变量求导,其他变量视为常数:
例子:对于
四、梯度 (Gradient)
4.1 梯度的定义
梯度是函数对所有变量偏导数组成的向量:
核心性质:梯度方向是函数增长最快的方向!
4.2 梯度的直觉
想象你在山地上,梯度就像是指示"最陡上坡方向"的指针:
- 梯度方向 → 上坡最快的方向
- 负梯度方向 → 下坡最快的方向(用于梯度下降!)
- 梯度大小 → 坡度的陡峭程度
4.3 梯度下降
梯度下降是所有机器学习优化的核心思想:
其中:
:模型参数 :学习率(步长) :损失函数 :损失函数关于参数的梯度
python
import numpy as np
def gradient_descent(f, grad_f, x_init, lr=0.01, n_steps=100):
"""
通用梯度下降实现
f: 目标函数
grad_f: 梯度函数
x_init: 初始点
lr: 学习率
"""
x = x_init.copy()
history = [x.copy()]
for _ in range(n_steps):
gradient = grad_f(x) # 计算梯度
x = x - lr * gradient # 沿负梯度方向更新
history.append(x.copy())
return x, history
# 示例:最小化 f(x) = x^2
f = lambda x: x**2
grad_f = lambda x: 2*x
x_min, history = gradient_descent(f, grad_f, x_init=np.array([5.0]))
print(f"最优解: {x_min}") # 接近 0五、链式法则与反向传播
5.1 链式法则
链式法则是反向传播的数学基础。对于复合函数:
则:
对于多变量,链式法则推广为:
5.2 反向传播示例
考虑一个简单的两层神经网络:
反向传播计算
每一项都可以用链式法则逐步计算!
python
import torch
# PyTorch 自动微分示例
x = torch.tensor([2.0], requires_grad=True)
y = x ** 2 + 3 * x + 1 # y = x² + 3x + 1
y.backward() # 自动计算梯度
print(x.grad) # dy/dx = 2x + 3 = 2*2 + 3 = 7六、泰勒展开
泰勒展开可以将任何复杂函数近似为多项式:
特别重要的例子:
这个展开式是 SVM 高斯核(RBF 核)能映射到无限维空间的数学原因!
在 XGBoost 中,对损失函数进行二阶泰勒展开来近似求解,这使得 XGBoost 可以快速找到最优分裂点。
七、总结:梯度下降的变体
| 方法 | 每次使用样本数 | 特点 |
|---|---|---|
| 批量梯度下降 (BGD) | 全部样本 | 稳定但慢 |
| 随机梯度下降 (SGD) | 1 个样本 | 快但震荡大 |
| 小批量梯度下降 (Mini-batch GD) | 32~256 个样本 | 实际中最常用 |